DATA MART

Reading time: 9 minutes
Imagine you run a candy store. Some of the goodies
are on display cases for quick access while the rest is in the storeroom. Now
let’s think of the sweets as the data required for your company’s daily
operations. Instead of combing through the vast amounts of all organizational
data stored in a data warehouse, you can use a data mart — a repository that
makes specific pieces of data available quickly to any given business unit.
Just like display cases in a store.
Nowadays, we’re living in the
era of Big Data. It’s difficult to operate a business without accumulating and
analyzing vast amounts of information. As a result, our lives are increasingly
reliant on data storage and processing.
According to the research
conducted by The Conversation, there are more than 59 zettabytes of data
created, shared, and stored worldwide. One zettabyte (ZB) equals a trillion
gigabytes. Yet, the experts expect the amount of data to increase three
times by 2025. And all this information has to be stored and analyzed to get helpful
insights.
This article is going to provide an in-depth explanation of what data marts are and how they store data for Business Intelligence purposes. You’ll also find out about the key types of data marts, their structure schemas, implementation steps, and more.
What is a data mart?

A data mart is a smaller subsection of a data warehouse built specifically for a particular subject area, business function, or group of users. The main idea is to provide a specific part of an organization with data that is the most relevant for their analytical needs. For example, the sales or finance teams can use a data mart containing sales information only to make quarterly or yearly reports and projections. Since data marts provide analytical capabilities for a restricted area of a data warehouse, they offer isolated security and isolated performance.
Data mart vs data warehouse vs data lake vs OLAP cube
Data lakes, data warehouses, and data marts are all data repositories of different sizes. Apart from the size, there are other significant characteristics to highlight.
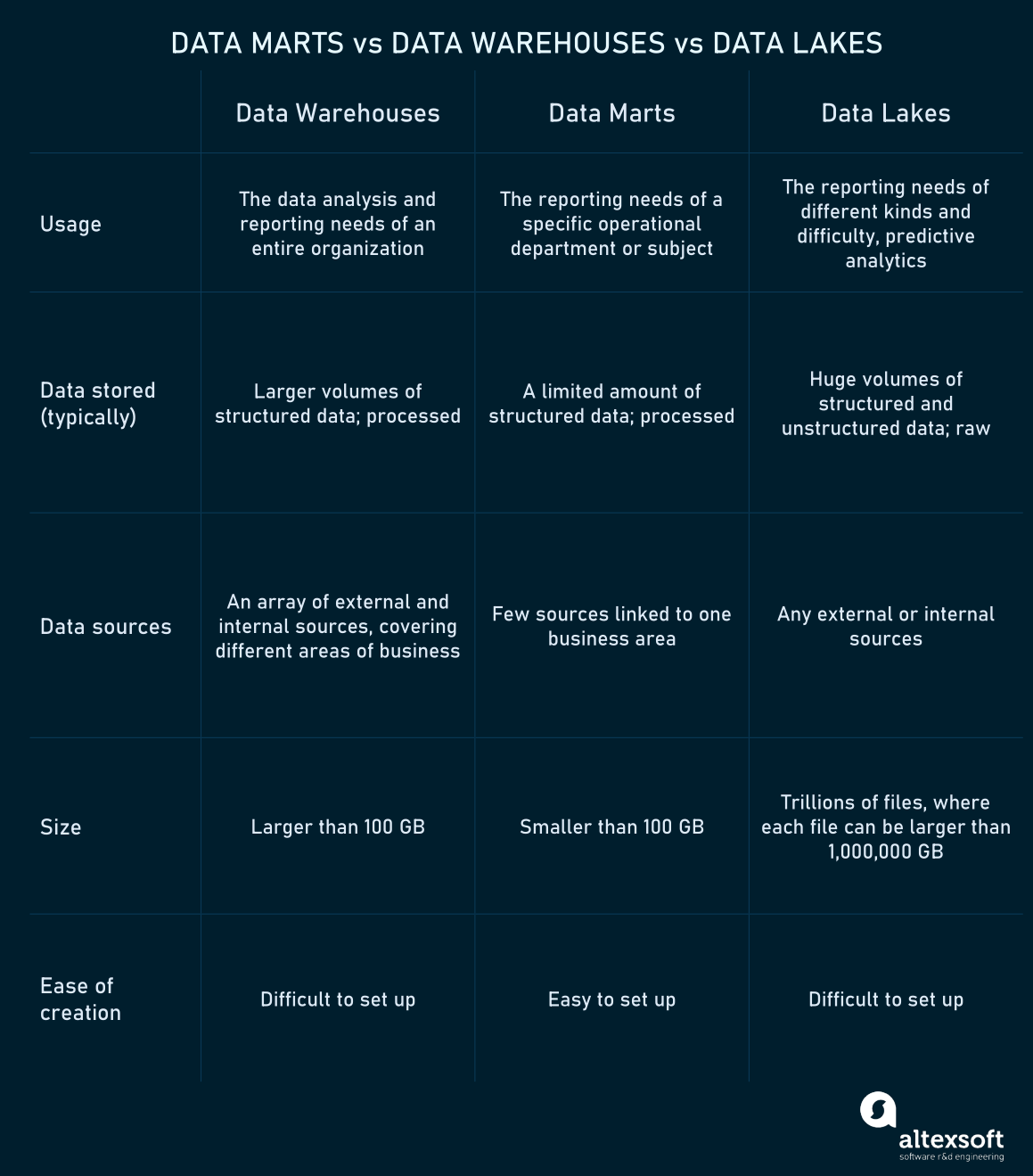
Key differences between data marts, data warehouses, and data lakes
Three types of cloud storage repositories
Three distinct types of cloud storage repositories exist today, each serving a different purpose to address a specific need:
Data lake
A data lake is a large repository of raw data, either unstructured or semi-structured. This data is aggregated from various sources and is simply stored. It is not altered to suit a specific purpose or fit into a particular format. To prepare this data for analysis involves time-consuming data preparation, cleansing, and reformatting for uniformity. Data lakes are great resources for municipalities or other organizations that store information related to outages, traffic, crime, or demographics. The data could be used at a later date to update DPW or emergency services budgets and resources.
Data warehouse
A data warehouse is an aggregation of data from many sources to a single, centralized repository that unifies the data qualities and format, making it useful for data scientists to use in data mining, artificial intelligence (AI), machine learning, and, ultimately, business analytics and business intelligence. Data warehousing could be used by a large city to aggregate electronic transactions from various departments, including speeding tickets, dog licenses, excise tax payments, and other transactions. This structured data would be analyzed by the city to issue follow-up invoicing and to update census data and police logs. It could also be used by a developer to aggregate terabytes of data generated by sensors on automobiles to aid in the decision-making process for an autonomous driving solution.
Data mart
A data mart is a subset of a data warehouse that benefits a specific set of users within the business or business unit. A data mart could be used by the marketing department of a manufacturing company to determine the ideal target demographic or persona to aid in the development of marketing plans. It could also be used by a manufacturing department to analyze performance and error rates to enable continuous improvement. Data sets within a data mart are often utilized in real-time, for current analysis and actionable results.
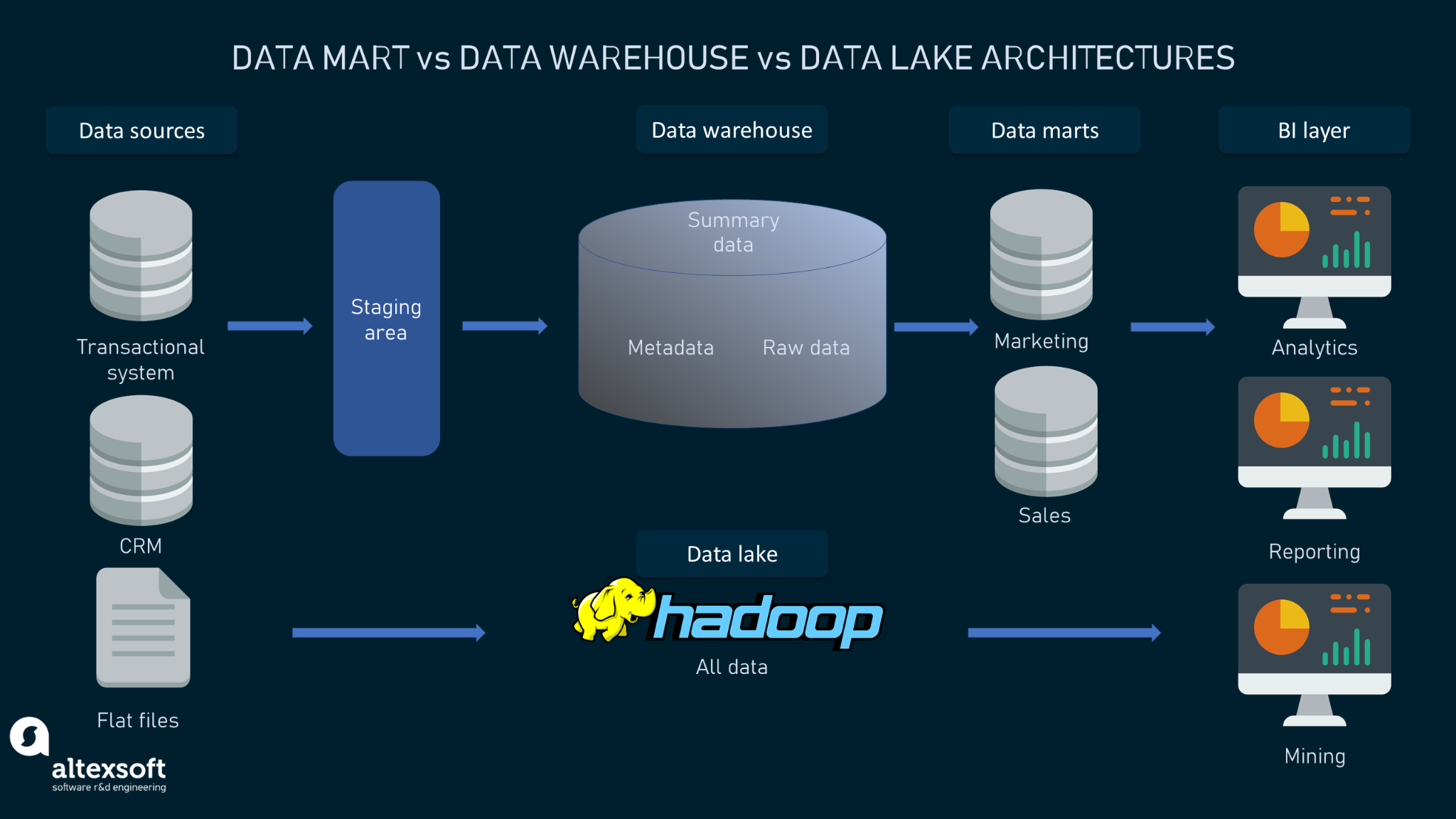
Data mart vs data warehouse vs data lake architectures
Data marts shouldn’t be confused with OLAP cubes either. An OLAP or Online Analytical Processing cube is the tool used to represent data for analysis in a multidimensional way. So, just like data warehouses, data marts can be used as the foundation for creating an OLAP cube. For example, a company has a data mart containing all the financial data. The company may wish to model an OLAP cube to summarize this data by different dimensions: by time, by product, or by city, to name a few.
Now that we’ve defined a data mart’s place on the map in relation to other data repositories, we’re moving on to a more descriptive explanation of their types and structure.
Types of data marts
Based on how data marts are related to the data warehouse as well as external and internal data sources, they can be categorized as dependent, independent, and hybrid. Let’s elaborate on each one.
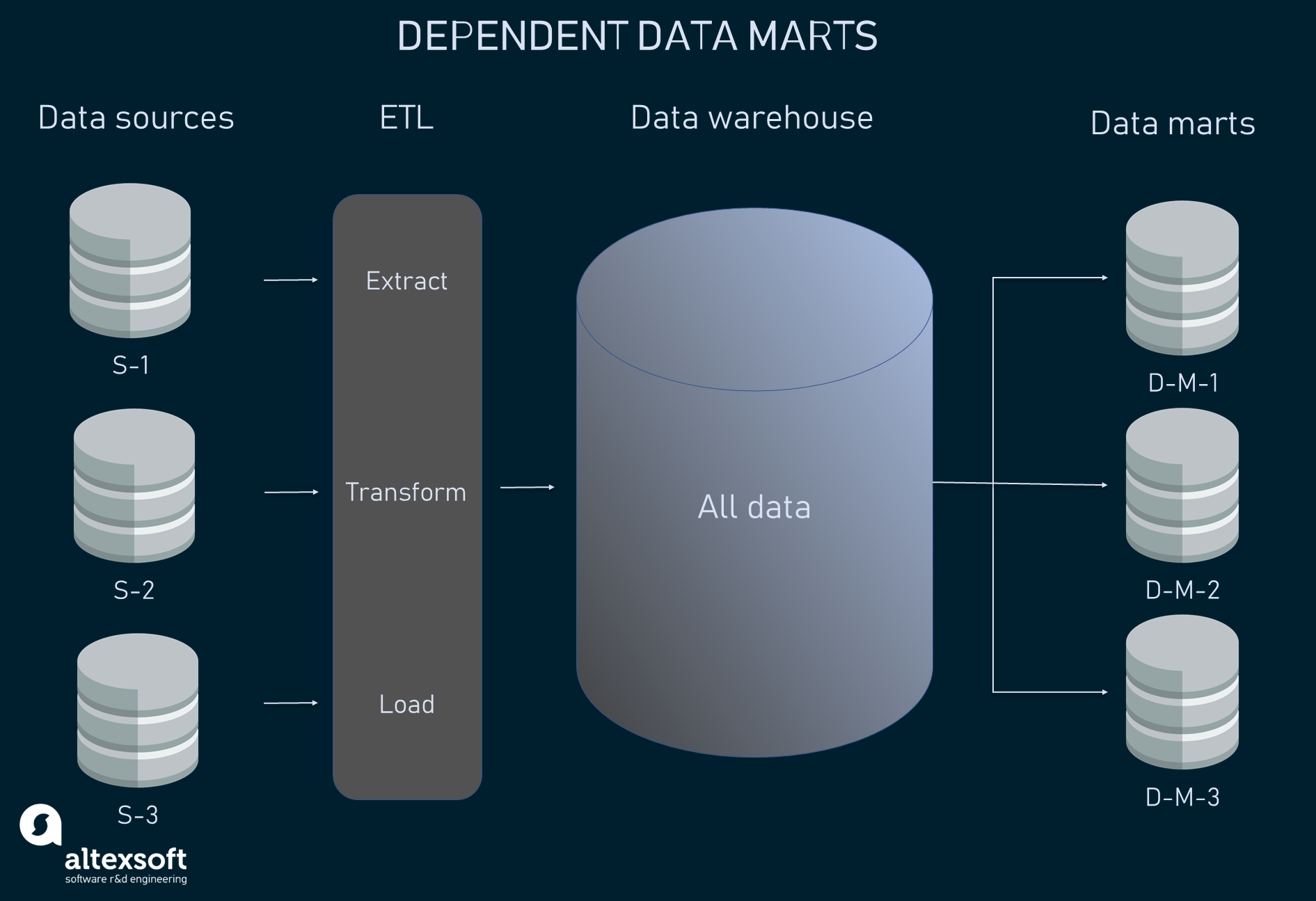
Dependent data marts
Dependent data marts are the subdivisions of a larger data warehouse that serves as a centralized data source. This is something known as the top-down approach — you first create a data warehouse and then design data marts on top of it. Within this sort of relationship, data marts do not interact with data sources directly. Based on the subjects, different sets of data are clustered inside a data warehouse, restructured, and loaded into respective data marts from where they can be queried.
Dependent data marts are well suited for larger companies that need better control over the systems, improved performance, and lower telecommunication costs.
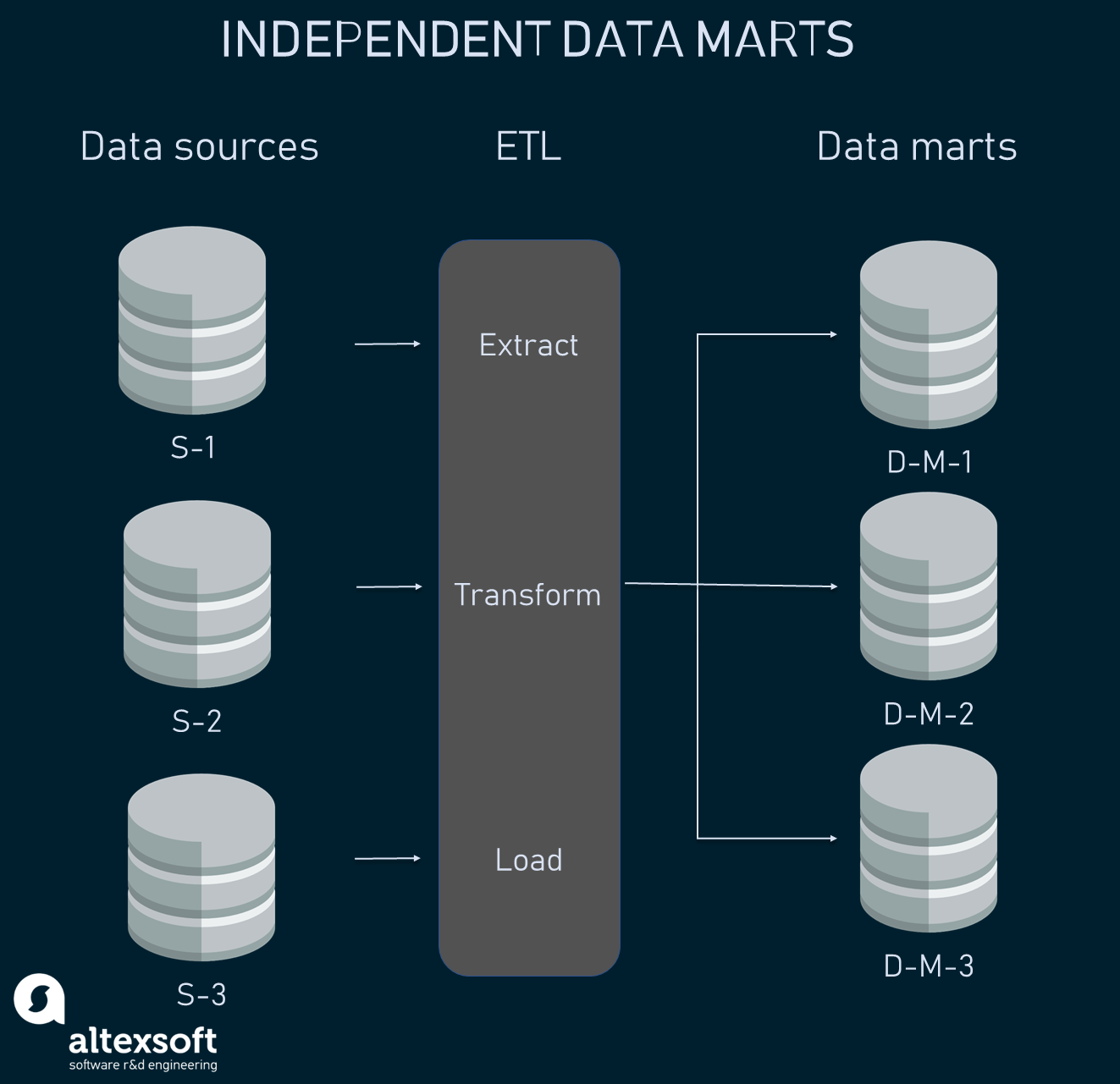
Independent data marts
Independent data marts act as standalone systems, meaning they can work without a data warehouse. They receive data from external and internal data sources directly. The data presented in independent data marts can be then used for the creation of a data warehouse. This approach is called bottom-up.
Often, the motivation behind choosing independent data marts is a shorter time to market. They work great for small to medium-sized companies.
So, the key difference between a dependent and independent data marts is in the way they get data from sources. The step involving data transfer, filtering, and loading into either a data warehouse or data mart is called the extract-transform-load (ELT) process. When dealing with dependent data marts, the central data warehouse already keeps data formatted and cleansed, so ETL tools will do little work. On the other hand, independent data marts require the complete ETL process for data to be injected.
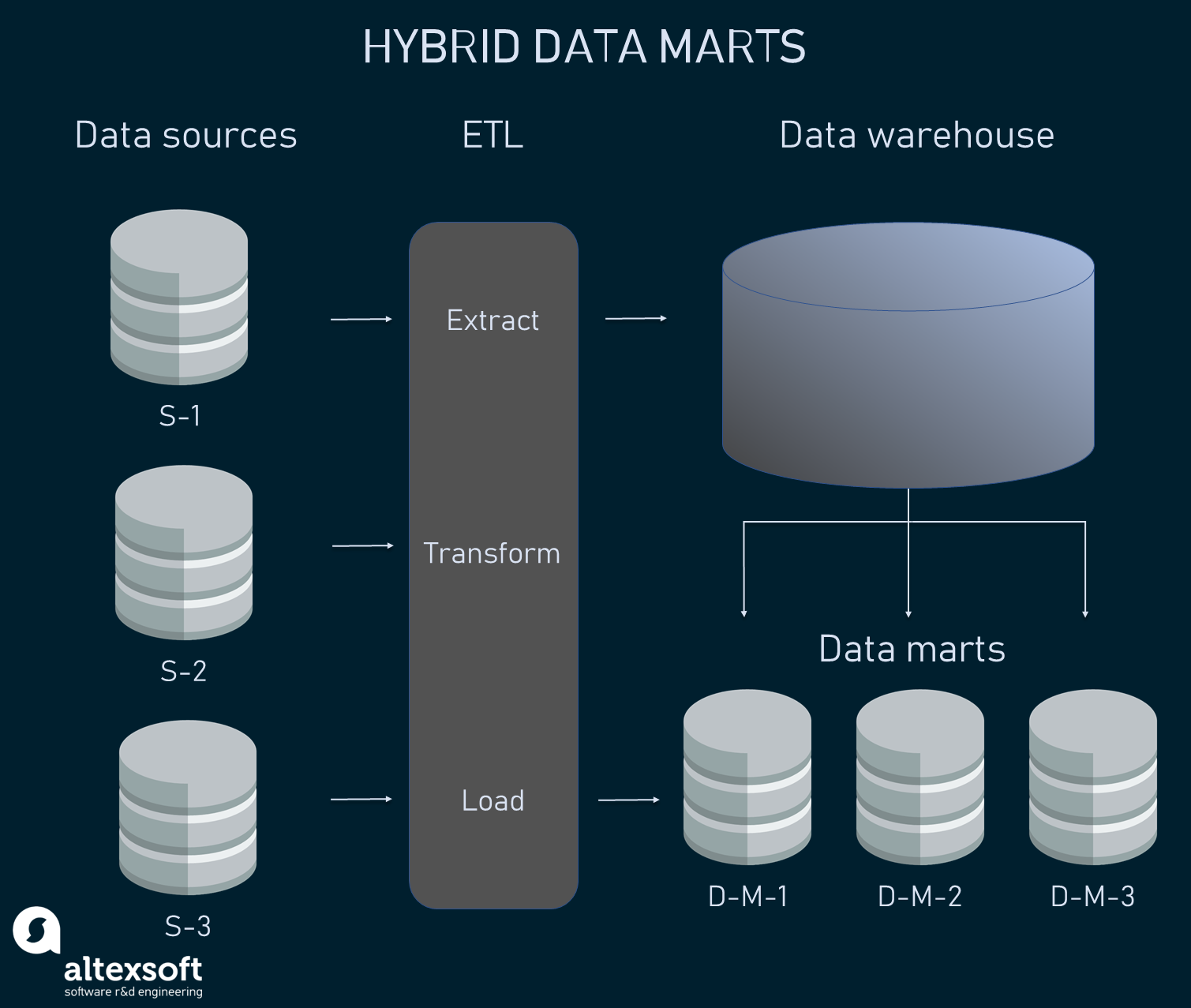
Hybrid data marts
Hybrid data marts integrate data from all existing operational data sources and/or data warehouses. This method collects the benefits and addresses the issues of both top-down and bottom-up approaches. Hybrid data marts are a good choice for organizations that have multiple databases.
Data mart structure schemas
Similar to traditional data warehouses, data marts use a relational approach to data modeling. A relation is a mathematical term for a table, which is a combination of rows and columns containing different values. To logically arrange pieces of data in a data mart, companies use two main schemas — star and snowflake. Both consist of a fact table and dimension tables with different levels of joints.
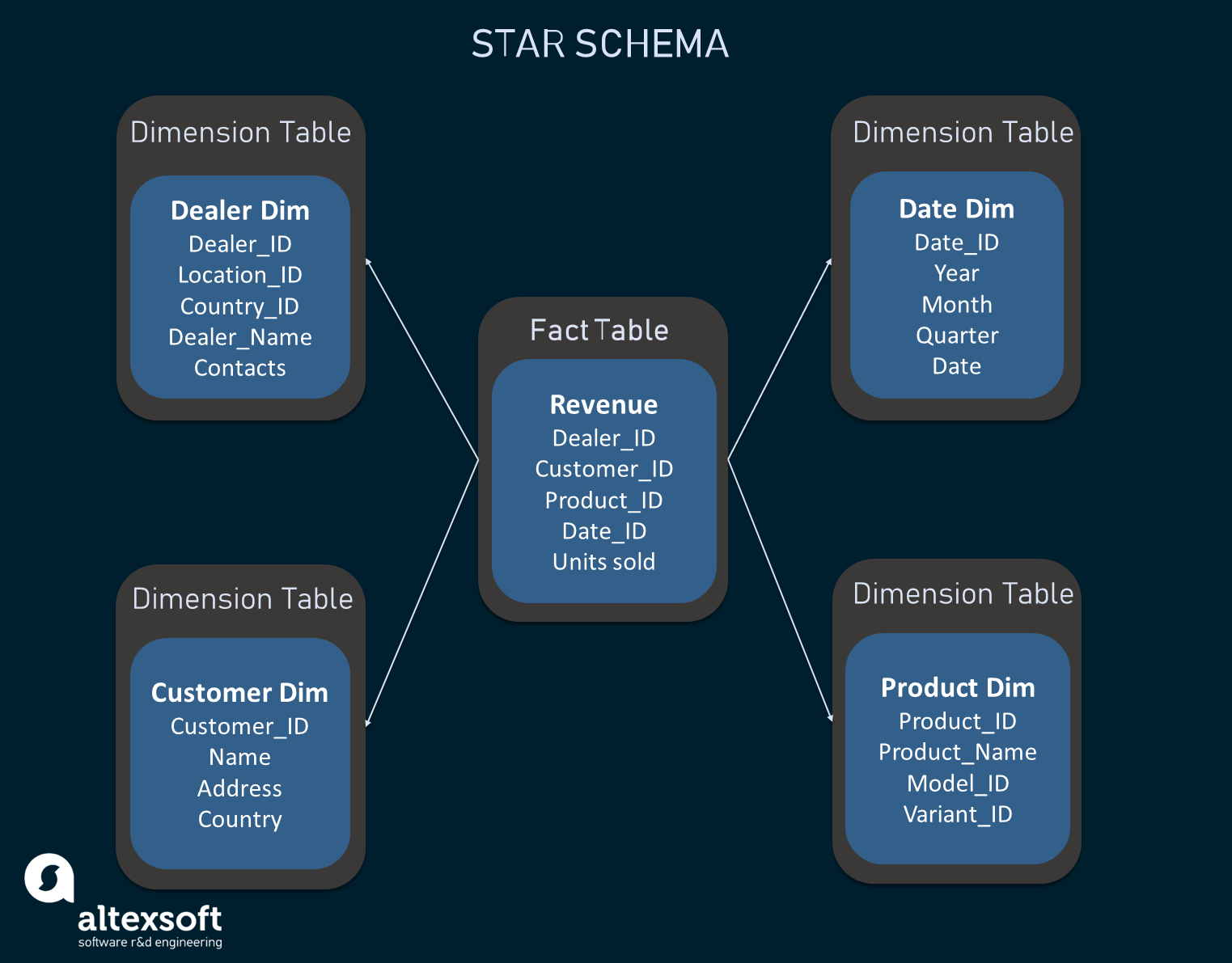
The example of star schema
Star schema, as the name suggests, resembles a star. It comprises only one fact table that is placed in the center of the model and breaks down into several dimension tables with denormalized data. This means that the data is redundant and that results in faster data retrieval as fewer joins are needed.
The fact table encompasses aggregated data designed to be used for analytical and reporting purposes while the dimension tables contain descriptions of the stored data. The star schema is a simple type of data mart structure as the fact table has only one link to each dimension table. As such, this model makes it easier to accomplish complex queries.
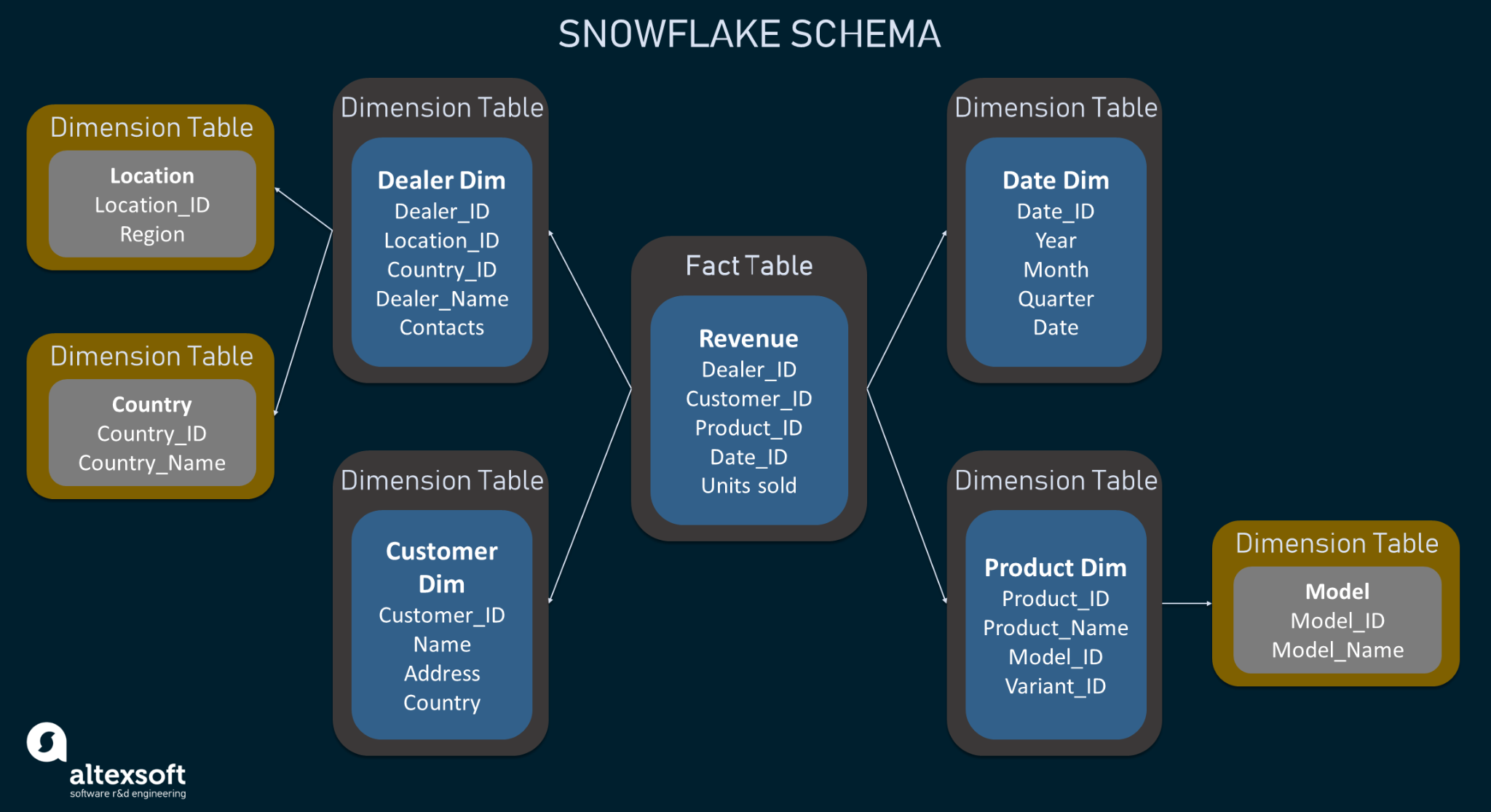
The example of snowflake schema
Snowflake schema has the star schema as its base, yet the data in dimension tables is normalized as it is split into additional dimension tables. The normalization of the dimension tables in the snowflake schema is reached by getting rid of attributes with few unique values and forming separate tables. Such an arrangement forms a sort of snowflake, hence the name of the schema. Though the snowflake schema protects data integrity more efficiently and takes up less disk space, querying becomes more complex because of many levels of joins between tables.
Data mart implementation steps
The process of creating data marts may be complicated and differ depending on the needs of a particular company. In most cases, there are five core steps such as designing a data mart, constructing it, transferring data, configuring access to a repository, and finally managing it. We’ll walk you through each step in more detail.
Data mart designing
The first thing you do when implementing a data mart is deciding on the scope of the project and its design. Since data marts are subject-oriented databases, this step involves determining a subject or a topic to which data stored in a mart will be related. In addition to collecting information about technical specifications, you need to decide on business requirements during this phase too. It is also necessary to identify the data sources related to the subject and design the logical and physical structure of the data mart.
Data mart constructing
Once the scope of work is established, here comes the second step that involves constructing the logical and physical structures of the data mart architecture designed during the first phase.
- Logical structure refers to the scenario where data exists in the form of virtual tables or views separated from the warehouse logically, not physically. Virtual data marts may be a good option when resources are limited.
- Physical structure refers to the scenario where a database is physically separated from the warehouse. The database may be cloud-based or on-premises.
Also, this step requires the creation of the schema objects (e.g., tables, indexes) and setting up data access structures.
It is essential to perform a detailed requirement collection before implementing any scenario since different organizations may need different types of data marts.
Data transferring
The third step covers all the tasks related to transferring data from sources to data marts:
- extracting information from target data sources,
- cleansing and converting data into a fitting format, and
- loading data into a data mart.
To perform the processes of extraction, transformation, and loading, ETL tools are used.
Data access configuring
Now that data is in data marts, it’s time to put it to use: making queries, analyzing data, creating reports, etc. The accessing step involves the following tasks:
- setting up the intermediate (meta) layer for the front-end application (the layer converts database structures into business terms so that end clients can access data from data marts easily);
- setting up and managing database structures like summarized tables; and
- setting up APIs (application programming interfaces) if required.
Data marts can be accessed via a command line or GUI (graphical user interface), which is a more user-friendly option.
Managing
The final step of the data mart implementation process encompasses different management tasks like:
- providing secure user access to data;
- optimizing and fine-tuning the system for better performance;
- adding and managing new data; and
- ensuring system availability and planning recovery scenarios.
Data mart use cases
Companies can become more agile and data-driven with the right approach to business intelligence and data analytics. Data marts were initially created to help companies make more informed business decisions and address unique organizational problems — those specific to one or several departments. There are quite a few cases where data marts can be used. We’ll cover the typical ones in this next paragraph.
Subject-focused data analytics
Data analytics play a crucial role in any business lifecycle. Data marts allow for more focused data analysis because they only contain records organized around specific subjects such as products, sales, customers, etc. Since there’s no extraneous information, businesses can discern clearer and more accurate insights.
For example, data marts can be used as on-premise or cloud-based destinations to consolidate all the marketing data and store it in a structured format. This allows marketing teams to reach a single source of truth and get a better handle on important metrics such as the return of investment (ROI), customer acquisition cost (CAC), and return on ad spend (ROAS). Data marts provide easy and fast access to important data points when needed. They can process complex queries and push the required data into corresponding reporting and data analytics tools.
Selective data access
Data marts can be used in situations when an organization needs selective privileges for accessing and managing data. This is often the case for big enterprises that can’t expose the entire data warehouse to all users. Building multiple dependent data marts can help protect sensitive data from unauthorized access and accidental writes.
Improved resource management
Providing each department with a separate data mart can be a good way to manage the imbalance of resource use by different organizational units. Say, the department running logistics operations does a lot of actions with a database daily. This may cause system malfunctions of other departments that perform fewer database queries. Eventually, this may decrease the performance effectiveness of the whole company. Data marts allow for using resources efficiently and effectively.
Time-limited data projects
Compared to corporate data warehouses that require significant time and effort, data marts are much easier and faster to set up: Data engineers and developers work with smaller amounts of data, fewer sources, and simpler schemas. On top of that, data marts are cheaper to implement than a DW. So, if you have time limitations in terms of completing a data project, data marts may be the way to go.
The “cloud-y” future of data marts
Businesses face an endless growth of information. Getting actionable, data-driven insights becomes difficult for those still using on-premises solutions. In the Big Data reality, data warehouses are progressively moving to the cloud — and so are data marts. Cloud solutions facilitate storing and sharing massive sets of data unlocking the true power of effective data analysis.
Cloud-based platforms offer flexible architectures with separate data storage and compute powers, resulting in better scalability and faster data querying. With a single repository containing all data marts in the cloud, businesses can not only lower costs but also provide all departments with unhindered access to data in real-time.
In addition, cloud data marts can be a great tool for machine learning purposes. Data marts contain all the relevant information connected to transactions, products, or customers for a given period of time. Because they’re credible, they can be used to build different ML models such as propensity models predicting customer churn or those providing personalized recommendations.
Excellent content. It will be beneficial to those who seek information about data mart.
ReplyDeleteGreat work!!
ReplyDeleteFantastic article! It was packed with useful information I could easily understand.
ReplyDeleteGreat blog buddy
ReplyDeleteGreat blog plus it also made me aware regarding issues and solutions related to big data
ReplyDelete👍
This comment has been removed by a blog administrator.
ReplyDeleteSuperior job
ReplyDeleteNice work
ReplyDeleteGreat work bro 🔥🔥🔥
ReplyDeleteInformation is beautifully structured allowing info to absorb quickly.
ReplyDeleteMost Usefull and knowledgeable information����
ReplyDeleteReally great information guys. Create more articles like this
ReplyDeleteBest information about database management system
ReplyDelete